Paragraph selector
Overview
At a glance, the paragraph selector is yet another grouping selector, which intelligently analyzes the input to convert into paragraphs, by taking into account the distances between both text lines and words in lines.
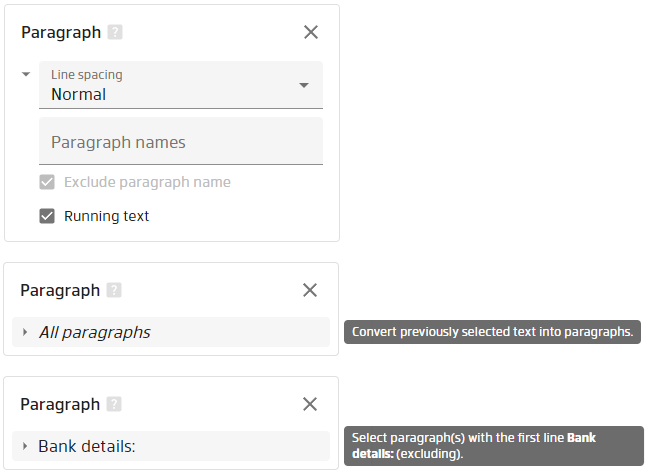
Properties
Line spacing
By specifying this, you can give the selector insight on how big the distance between the lines will be.
Paragraph names
Defines list of paragraph names (the first line of a paragraph is considered as it's name). If not left empty, this property makes this selector more advanced as only the text block following the paragraph name will be extracted.
With a non-empty paragraph name, the Paragraph selector can be used as the first step of the extraction pipeline. It perfectly fits the values to be extracted when they are located in a column under a static key.
Exclude paragraph name
If checkbox is checked paragraph name would be excluded from resulted recognized paragraph.
Running text
If checkbox is not checked the resulted recognized paragraph would contain lines joined by new line character. Otherwise, lines would be joined into one by single space character.
Result overview
This selector extracts text as paragraphs (see type of output in Picker selector).
The format and example of the actual result produced by the pdf2Data Engine is described in Recognition result specification.
Depending on the parameters you can receive slightly different results. See the following examples.
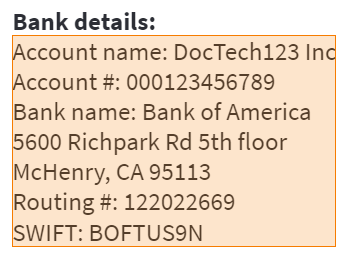
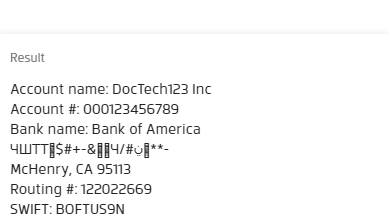
1. Named paragraph

extracts all bank details:
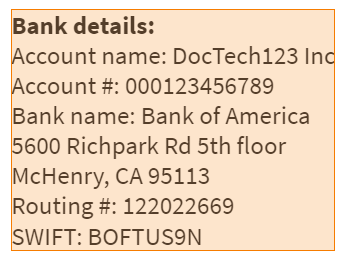
2. Include paragraph name

extracts with included paragraph name:
3. Running text is checked
result joined by single space character:

4. Running text is not checked
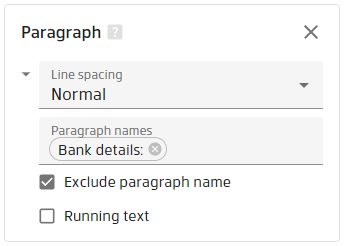
result joined by new line character:
Specification
To see more information about properties and expert usage visit specification page.